这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation。
首先,我们先要来个直观的印象,这是你以为的Hadoop集群:
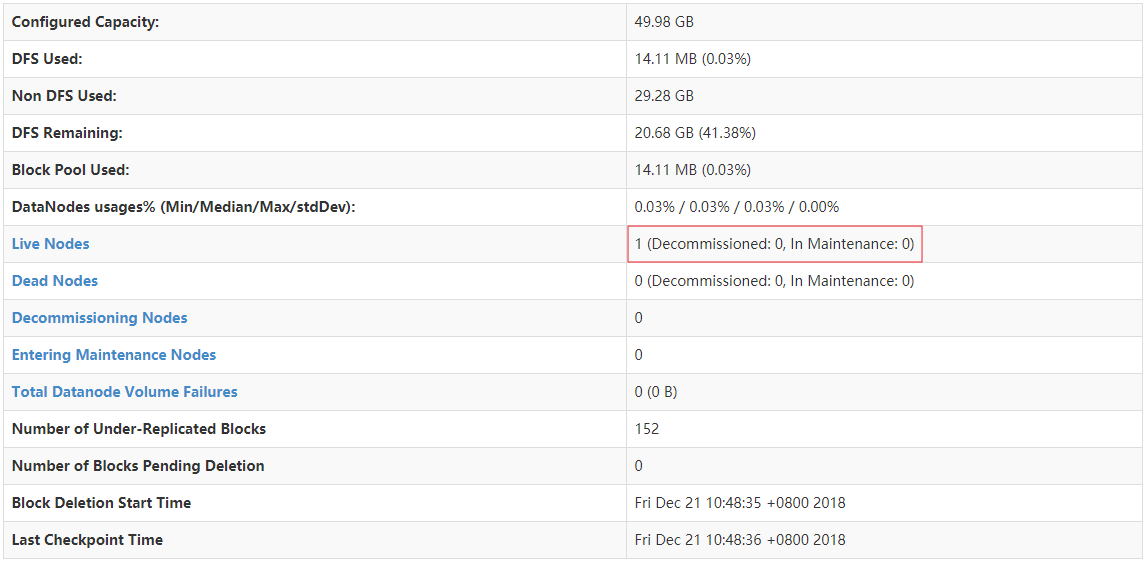
这是真实世界的Hadoop集群:
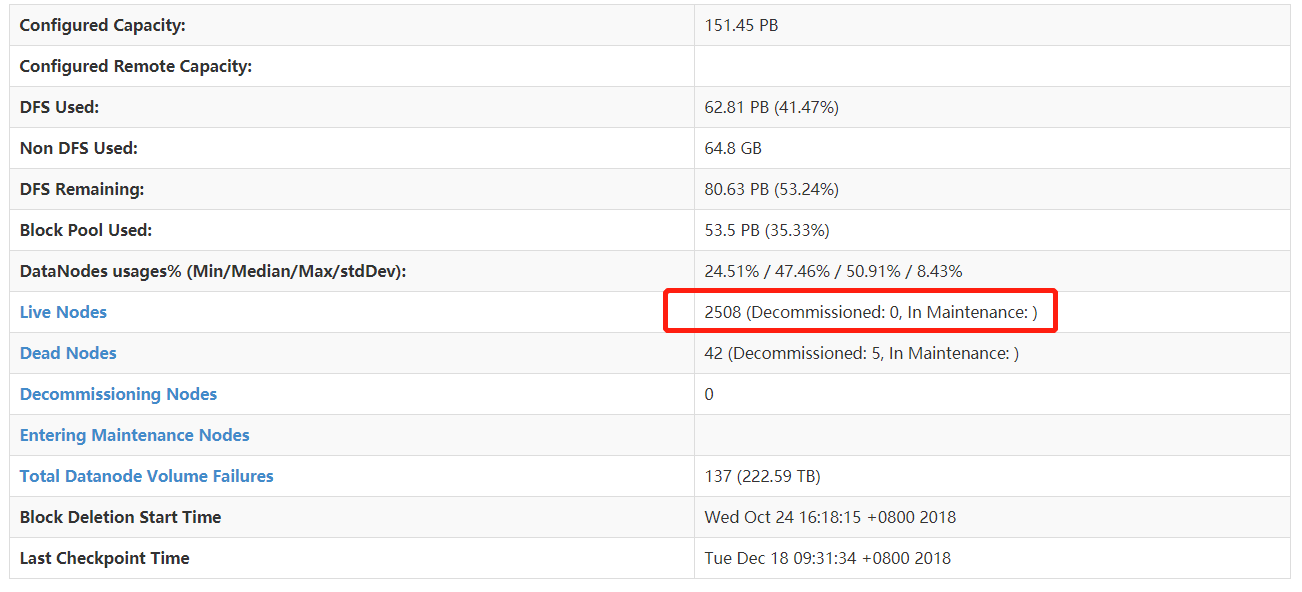
因为,NameNode(下称NN)中的元数据记录了各个数据块的存储位置。
所以,元数据的大小,与数据块的数量成正比。
当集群存储的数据规模到达一定程度时,NN将成为整套系统中的瓶颈所在。NN的存储能力是有限的,不管是磁盘存储还是内存存储。
为了解决这个问题,HDFS中引入了联邦(Federation)的概念。
联邦:由若干具有国家性质的行政区域(有国、邦、州等不同名称)联合而成的统一国家,各行政区域有自己的宪法、立法机关和政府,联邦也有统一的宪法、立法机关和政府。—— 维基百科
体现在HDFS上,就是“集权”到“分权”的过程,引入了多对NN(Active NN + Standby NN这里称为一对),让他们各自实现“区域自治”。
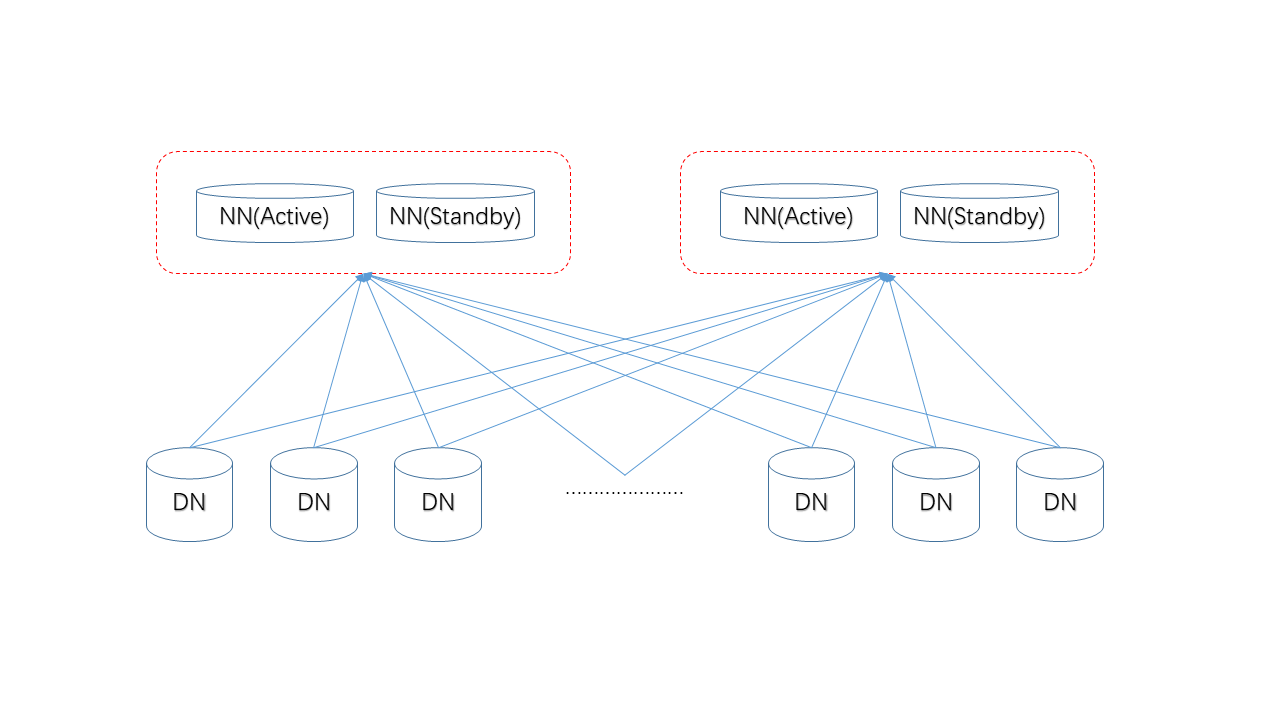
物理上是这样的,所有的DN(DataNode)需向所有的NN汇报状态。
逻辑上是这样的,一对NN只负责管理属于自己名称空间下的目录。
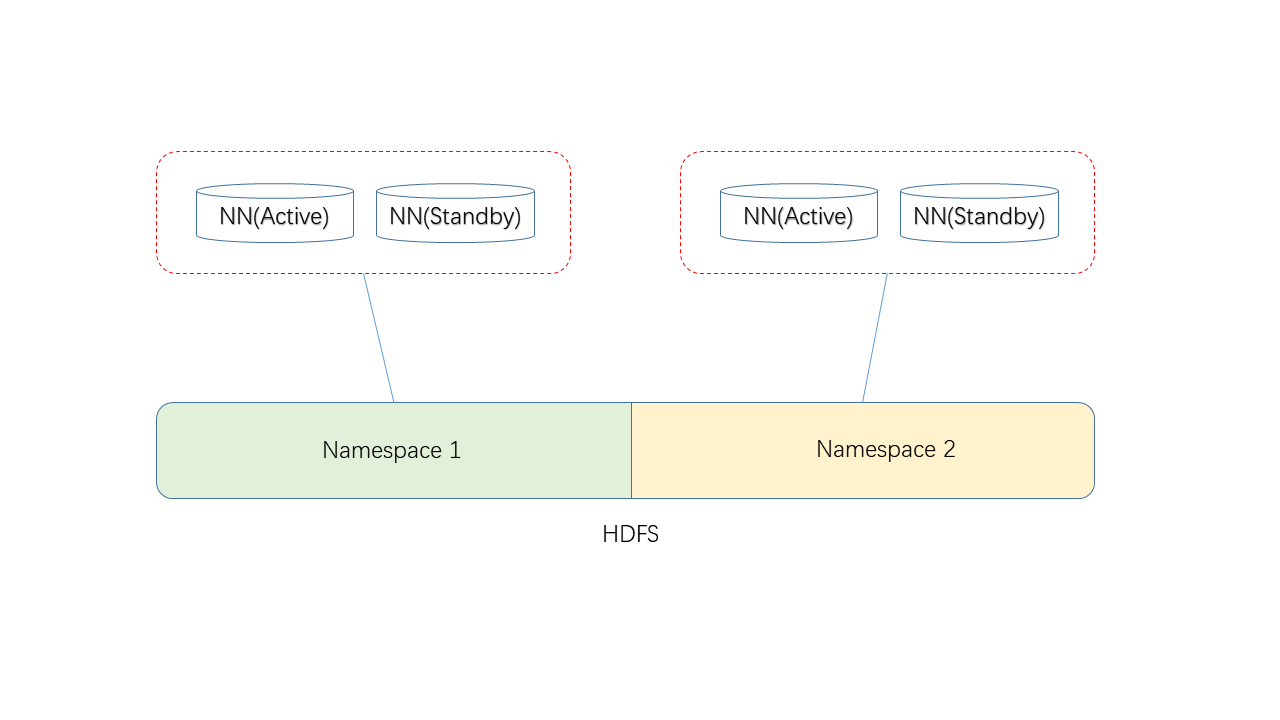
因此,并不是某对NN管理某些DN,而是对HDFS进行划分,即逻辑划分。
上面这样规模的集群,有可能划分出数十个“邦”,各自管理“邦”内的数据,这样就基本实现了NN的水平扩展,同时,还对提高整个系统的可用性有帮助,毕竟,某一对NN宕机,只会对系统产生局部影响。
注:HDFS联邦并不强制要求各NN都做HA,只是通常是这样配置的,即每个“邦”的NN都是成对出现的。
好了,关于HDFS的所有介绍就先到这,那些没讲到的,都不重要(误),下期我们将开始介绍新的内容:MapReduce的基本概念。Cheers!
公众号 程序员杂书馆,大数据内容持续更新中,欢迎关注!
